
TL;DR: RCM (Reliability-Centered Maintenance) is a structured methodology for determining the optimal maintenance strategy for each asset based on its function, failure modes, failure consequences, and operating context. The methodology was developed by United Airlines in the 1960s, formalized by Nowlan and Heap in 1978, and adapted for industrial use by John Moubray in the 1980s. RCM is structured around seven questions defined in SAE JA1011 (current revision November 2024) covering function, functional failures, failure modes, failure effects, failure consequences, proactive tasks, and default actions. Failures are classified into four consequence categories – hidden, safety/environmental, operational, and non-operational – that drive task selection. RCM evaluates three proactive task categories in order of preference (on-condition, scheduled restoration, scheduled discard) and falls back to default actions (failure-finding, redesign, run-to-failure) when no proactive task is appropriate. RCM is resource-intensive and many “RCM” implementations do not satisfy SAE JA1011 criteria. For most operations with mature PM programs, PM Optimization (PMO) delivers most of RCM’s value at roughly one-sixth the cost. This guide walks through the seven questions with worked examples, the consequence categories, the task hierarchy, the variants (RCM2, RCM3, MSG-3, classical RCM, streamlined RCM, PMO), and the honest assessment of when RCM, PMO, or alternatives fit best.
The Short Answer
RCM tells you what kind of maintenance is appropriate for each failure mode based on what happens when it fails. The methodology does not prescribe specific maintenance tasks. It provides a framework for deciding whether a failure mode needs proactive maintenance, what kind of proactive maintenance, and what to do if no proactive maintenance is appropriate.
The structural backbone is seven questions defined by SAE JA1011:
1. Functions — What is the asset supposed to do?
2. Functional failures — In what ways can it fail to do that?
3. Failure modes — What causes each functional failure?
4. Failure effects — What happens when each failure occurs?
5. Failure consequences — In what way does each failure matter?
6. Proactive tasks — What can be done to predict or prevent each failure?
7. Default actions — What should be done if a suitable proactive task cannot be found?
Most operations with mature maintenance programs do not need full RCM. They need PM Optimization, which delivers most of RCM’s value at a fraction of the cost. RCM is the right tool for green-field maintenance program development, critical equipment where coverage gaps would be dangerous, or operations where the existing PM plan is fundamentally broken. The honest assessment of when RCM is and is not appropriate is the most important decision in this methodology.
The History: Aviation, Department of Defense, and SAE Standardization
RCM originated in the commercial aviation industry in the 1960s. The introduction of the Boeing 747, DC-10, and L-1011 created a problem: traditional fixed-interval overhaul approaches that worked for earlier aircraft were producing massive cost overruns without improving reliability for the new wide-body jets. The FAA and the airline industry formed a Maintenance Steering Group to study the problem, producing MSG-1 (1968) and MSG-2 (1970) for commercial aviation maintenance program development.
In 1974, the U.S. Department of Defense commissioned United Airlines to write a report on the techniques used by commercial aviation to develop cost-efficient maintenance programs. Stanley Nowlan and Howard Heap of United Airlines published the resulting report – titled “Reliability-Centered Maintenance” – in 1978. Tom Matteson, then Vice President of Maintenance Planning at United Airlines, had originated the program but left the company months before publication and received no authorial credit. Howard Heap died shortly after the report’s publication.
The Nowlan-Heap report demonstrated empirically that the assumptions underlying traditional preventive maintenance were largely wrong. The research showed that only 11 percent of components studied could benefit from a limit on their operating age, while 89 percent of components either failed at random or showed no relationship between age and failure probability. For these components, fixed-interval overhauls did not prevent failures and often caused additional failures by introducing infant mortality from the overhaul work itself.
The methodology was adopted by the U.S. military beginning in the mid-1970s and by the U.S. commercial nuclear power industry in the 1980s. In 1983, Stan Nowlan began collaborating with John Moubray to adapt RCM to industries beyond aviation. Moubray’s adaptation, released as RCM2 in 1990 and detailed in his 1991 book “Reliability-Centered Maintenance” (with a second edition in 1997), became the most widely deployed RCM methodology in industrial applications globally.
By the late 1990s, the widespread use of “RCM” for methodologies that deviated significantly from the original concepts had become a problem. SAE International published JA1011 in August 1999, defining the minimum criteria that any process must satisfy to be called RCM. The standard was revised in August 2009 and again in November 2024 (current version JA1011_202411). The companion standard JA1012 provides implementation guidance. SAE JA1011 conformance is now the recognized test for whether a methodology genuinely qualifies as RCM, and many methodologies marketed as RCM do not satisfy JA1011 criteria.
John Moubray died unexpectedly in January 2004 at age 54. His work continues through the Aladon Network, which has developed RCM3 as a continuation of RCM2 incorporating modern asset management standards including ISO 55000 and ISO 31000.
Question 1: Functions and Performance Standards
RCM begins with function definition because failures can only be identified relative to intended function. SAE JA1011 requires that the operating context shall be defined and that all functions of the asset shall be identified, including primary functions, secondary functions, and the functions of all protective devices.
Function definition is where most RCM analyses go wrong. Operations frequently treat function as obvious and skip rigorous definition, then discover their failure mode lists are incomplete because some functions were never explicitly identified. A centrifugal pump’s primary function might be “to pump water from tank X to tank Y at not less than 800 liters per minute.” Secondary functions include containment (“to contain the water in the pump”), structural integrity (“to maintain mechanical integrity under expected operating loads”), and noise control. Each function generates its own failure modes.
Performance standards are the threshold at which the asset is considered to have failed to fulfill the function. The pump above fails its primary function at less than 800 L/min – not at zero flow. Performance standards must be quantified where possible because they define when failures begin, not just when they become obvious.
The operating context matters because the same physical asset can have different functions and different failure consequences in different applications. A pump moving water in a non-critical service has different RCM analysis outcomes than the same pump moving sulfuric acid in a process safety application. SAE JA1011 specifically requires that the operating context shall be defined before the analysis proceeds.
Question 2: Functional Failures
A functional failure is the inability of an asset to fulfill a function to the standard required by its user. SAE JA1011 requires that all the failed states associated with each function shall be identified.
Functional failures include total inability to function, partial failures where the asset still functions but at unacceptable performance, and failures where the asset operates outside specified quality or accuracy limits. The pump above could experience multiple functional failures: complete loss of flow, flow below 800 L/min, contamination of pumped fluid, external leakage, or excessive vibration affecting downstream equipment.
Each functional failure generates its own analysis stream through the remaining questions. Operations that combine multiple functional failures into a single category miss failure modes that are specific to particular failure states.
Question 3: Failure Modes
A failure mode is any event that is reasonably likely to cause a functional failure. SAE JA1011 specifies that “all failure modes which are reasonably likely to cause each functional failure shall be identified” — note the “reasonably likely” qualifier, which Moubray emphasized as critical to making RCM practical rather than exhaustive.
Failure modes are typically identified through Failure Mode and Effects Analysis (FMEA) integrated into the RCM process. Our FMEA methodology guide covers this analytical step in detail. The integration matters: FMEA is the analytical engine that produces the failure mode list; RCM is the decision framework that determines what to do about each failure mode. Operations performing one without the other typically produce incomplete reliability programs.
Failure modes should be specific enough to drive task selection. “Bearing failure” is too generic; “bearing failure due to inadequate lubrication” suggests on-condition oil analysis or scheduled regreasing, while “bearing failure due to overload from misalignment” suggests vibration monitoring and alignment checks. The specificity of failure mode definition determines the quality of subsequent task selection.
Question 4: Failure Effects
Failure effects describe what happens when each failure occurs. SAE JA1011 requires that the failure effects shall describe what would happen if no specific task is done to anticipate, prevent, or detect the failure, including evidence that the failure has occurred, threats to safety or environment, effects on operations, and physical damage that the failure causes.
The “if no specific task is done” framing matters. Failure effects describe what would happen in the absence of intervention, not what currently happens with existing maintenance in place. This framing prevents the common error of describing failure effects that are masked by current maintenance practices.
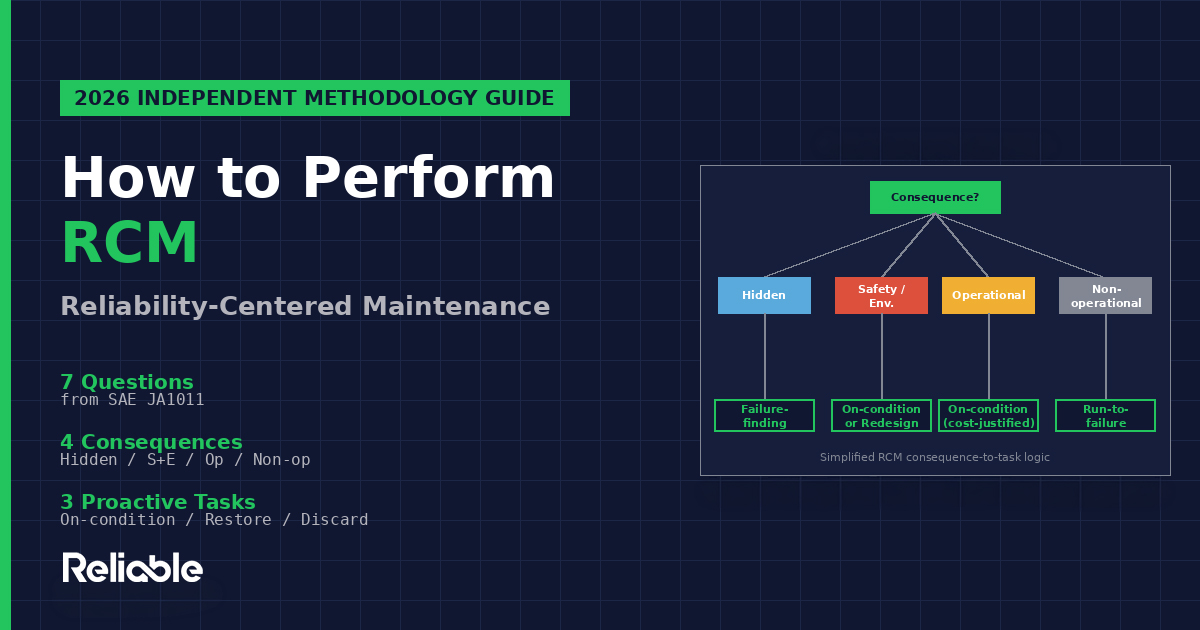
Question 5: Failure Consequences – The Four Categories
Failure consequence classification is the most consequential step in RCM because the consequence category determines what kind of proactive task is justified. RCM2 classifies consequences into four categories:
Hidden failure consequences. Hidden failures have no direct impact under normal operating conditions, but they expose the organization to multiple failures with potentially serious consequences. Hidden failures are typically associated with protective devices that are not fail-safe – a pressure relief valve, a fire suppression system, an emergency shutdown system. The hidden failure of the protective device only becomes evident when a primary failure occurs that the protective device should have managed. Most protective devices have hidden failures that require failure-finding tasks because the protective function is not exercised under normal operations.
Safety and environmental consequences. A failure has safety consequences if it could kill or injure someone. It has environmental consequences if it could lead to a breach of any corporate, regional, national, or international environmental standard. These consequences override economic considerations — RCM requires action to reduce safety and environmental failure probabilities to a tolerable level regardless of cost, including redesign if no proactive task is technically feasible.
Operational consequences. A failure has operational consequences if it affects production output, product quality, customer service, or operating costs above and beyond the direct cost of repair. Operational consequence decisions are economic – proactive tasks are justified when the cost of the task is less than the cost of the operational consequence over the same period.
Non-operational consequences. Non-operational consequences apply to evident failures that affect neither safety nor production, involving only the direct cost of repair. Proactive tasks are justified only when the cost of the task is less than the cost of the failure repair itself. For many failure modes with non-operational consequences, run-to-failure is the technically defensible policy.
The hidden vs evident distinction comes first in the consequence analysis because failure-finding tasks are the only appropriate response to most hidden failures. The safety/environmental vs operational vs non-operational distinction then drives task selection for evident failures.
Question 6: Proactive Tasks – The Hierarchy
For each failure mode, RCM evaluates proactive tasks in a specific order of preference. SAE JA1011 specifies that proactive tasks shall be identified that are both technically feasible and worth doing. Three proactive task categories exist:
On-condition tasks. On-condition tasks check for evidence of pending failure – vibration analysis, oil analysis, thermography, ultrasonic inspection, motor circuit analysis, performance monitoring. RCM2 requires that on-condition tasks satisfy four criteria to be technically feasible: it must be possible to define a clear potential failure condition, the P-F interval must be reasonably consistent, it must be practical to monitor the item at intervals less than the P-F interval, and the net P-F interval must be long enough to be of some use. On-condition tasks are evaluated first because they generally produce better economic outcomes than time-based tasks when the failure mode exhibits detectable degradation.
Scheduled restoration tasks. Scheduled restoration tasks (time-based overhaul) restore component capability at specific intervals regardless of condition at the time. Restoration tasks are technically feasible only when the failure mode shows a clear age at which conditional probability of failure begins to rise rapidly (the wear-out region in Weibull terms). Restoration tasks are evaluated when on-condition tasks are not technically feasible.
Scheduled discard tasks. Scheduled discard tasks (time-based replacement) replace components at specific intervals regardless of condition. Like restoration tasks, discard tasks require a clear wear-out characteristic. Discard tasks are evaluated when neither on-condition nor restoration is technically feasible or worth doing.
The Nowlan-Heap research demonstrated that only about 11 percent of components show the age-related failure characteristic that justifies time-based tasks. For the other 89 percent of components – which fail at random or show no age relationship – time-based tasks do not improve reliability and often cause additional failures. This is one of the foundational findings that distinguishes RCM from traditional preventive maintenance approaches.
Question 7: Default Actions
When no proactive task is technically feasible or worth doing, RCM specifies default actions. The choice of default action depends on the failure consequence category:
Failure-finding tasks are appropriate for hidden failures. Failure-finding tasks check whether a hidden function still works, typically by exercising a protective device on a scheduled interval. Failure-finding is technically a default action, not a proactive task, because it does not prevent the failure – it detects whether the failure has already occurred. The failure-finding interval (FFI) calculation balances the probability of multiple failures against the cost and operational impact of the testing.
Redesign is mandatory for failure modes with safety or environmental consequences when no proactive task is technically feasible. RCM does not permit accepting safety or environmental consequences as a maintenance policy. If maintenance cannot reduce the failure probability to a tolerable level, the design must change to eliminate the failure mode or its consequences.
Run-to-failure (no scheduled maintenance) is acceptable only for failure modes with non-operational consequences. Run-to-failure means accepting that the failure will occur and addressing it reactively. This is a defensible RCM decision when the cost of any proactive task exceeds the cost of the failure repair, and when the failure has no safety, environmental, or operational consequences. Operations that interpret RCM as recommending run-to-failure broadly are typically misapplying the methodology – run-to-failure is appropriate only for a specific consequence category.
Redesign is also available for hidden failures and operational consequences when proactive tasks are not adequate. The choice between redesign and acceptance of consequences depends on the operational context and the cost-benefit comparison.
Worked Example 1: Industrial Pump RCM Analysis
A simple RCM analysis for one critical asset. The asset is a centrifugal water pump in a chemical plant cooling water service.
Operating Context: The pump operates continuously to circulate cooling water through process heat exchangers. Loss of cooling water flow causes process heat exchanger fouling within hours and process upset within 24 hours. A duty/standby configuration with automatic switchover is in place.
Question 1 – Functions:
- Primary: Pump cooling water from cooling tower basin to process heat exchangers at not less than 800 L/min at design discharge pressure
- Secondary: Contain the cooling water within the pump casing
- Secondary: Maintain mechanical integrity under expected operating loads and thermal cycling
Question 2 – Functional Failures (primary function only, for brevity):
- 2A: Complete loss of flow
- 2B: Flow reduced below 800 L/min but above zero
Question 3 – Failure Modes (for functional failure 2A only):
- Bearing seizure
- Mechanical seal failure causing complete loss of pumped fluid
- Coupling failure
- Motor failure
- Suction blockage
- Shaft fracture
Question 4 – Failure Effects (for “bearing seizure” failure mode): Bearing seizes, motor amperage spikes and trips on overcurrent protection. Pump stops within seconds. Standby pump starts automatically. No process impact under normal conditions because of standby configuration. Bearing replacement requires pump removal, taking 8 to 16 hours of active maintenance work. If standby pump is unavailable when seizure occurs (multiple failure scenario), cooling water flow stops and process upset begins within hours.
Question 5 – Failure Consequences (for bearing seizure): Evident operational consequences. Failure is evident because of motor trip and standby start. Operational impact depends on whether standby is available. Direct repair cost plus lost production cost during repair window if standby is also unavailable.
Question 6 – Proactive Tasks Evaluated:
- On-condition: Vibration monitoring (quarterly with handheld instrument or continuous online if cost-justified) – technically feasible because bearing degradation produces detectable vibration signatures with adequate P-F interval
- On-condition: Oil analysis quarterly – technically feasible for early detection of bearing material in lubricant
- Scheduled restoration: Bearing inspection at 5-year intervals – possible but lower value than on-condition because failure pattern is not strongly age-related
Selected Tasks:
- Vibration monitoring quarterly using handheld instrument with FFT analysis
- Oil analysis quarterly
- No scheduled restoration (on-condition tasks address the failure mode)
This single-asset analysis demonstrates the RCM workflow. A complete pump analysis would proceed through all functional failures and all failure modes, generating dozens to hundreds of analysis lines. The output is not just the maintenance tasks – it is the documented justification for why those specific tasks address those specific failure modes for those specific consequences.
Worked Example 2: The Four Consequence Categories
This example demonstrates how consequence classification drives task selection. Five failure modes from different equipment, each with different consequence categories.
| Failure Mode | Consequence | Selected Task |
|---|---|---|
| Pressure relief valve fails to open at setpoint | Hidden (protective device) | Failure-finding: Bench test annually |
| Process line corrosion under insulation causing release of toxic gas | Safety / environmental | On-condition: API 570 inspection at risk-based intervals; redesign if no acceptable inspection frequency |
| Production conveyor belt fails causing line stoppage | Operational | On-condition: Visual inspection weekly plus belt thickness measurement quarterly |
| Office HVAC fan motor failure (redundant unit available) | Non-operational | Run-to-failure (no scheduled maintenance) |
| Emergency shutdown valve fails to close on demand | Hidden + safety | Failure-finding: Functional test quarterly; redesign if achievable test interval inadequate |
The same equipment can have different consequence categories for different failure modes, and different equipment can have the same consequence category. The pattern that drives task selection is consistent: hidden failures get failure-finding, safety failures get on-condition or redesign, operational failures get cost-justified proactive tasks, and non-operational failures often get run-to-failure.
Notice the run-to-failure decision for the office HVAC motor. This is a defensible RCM decision because the failure has only non-operational consequences (a redundant unit is available, no production impact, no safety impact, no environmental impact), and proactive maintenance cost would exceed the failure repair cost over the equipment’s life. Operations that perform PMs on equipment like this without RCM justification are wasting resources that could be better deployed on equipment with higher consequences.
Worked Example 3: Common Mistakes Walkthrough
This example shows what RCM looks like when it’s done badly – patterns that are common in operations that treat RCM as a deliverable rather than as analysis.
The Setup: An industrial site is asked to perform RCM on a critical compressor system. The site has 90 days to deliver “an RCM analysis” before a customer audit. The maintenance manager assigns the project to one mechanical engineer.
Mistake 1: Single-person analysis. SAE JA1011 effectively requires cross-functional analysis because no single person has adequate knowledge of operations, maintenance, design, and field experience to identify all reasonably likely failure modes. Single-person RCM analyses systematically miss failure modes that the absent perspectives would identify. The analysis fails JA1011 conformance even before any specific question is answered.
Mistake 2: Skipping Question 1 or treating function as obvious. The engineer documents that the compressor’s function is “to compress air” without quantifying performance standards or identifying secondary functions. Failure modes related to oil contamination, noise emissions, vibration transmission to adjacent equipment, and protective device functions are all missed because the corresponding functions were never identified.
Mistake 3: Conflating failure modes with failure effects. The engineer documents “compressor doesn’t work” as a failure mode rather than as an effect of underlying failure modes (motor failure, bearing failure, valve failure, control system failure, etc.). The analysis cannot proceed to meaningful task selection because the failure modes are too generic.
Mistake 4: Treating all failures as having operational consequences. Without rigorous consequence classification, the engineer defaults to “operational consequences” for all evident failures and skips the hidden failure analysis entirely. Protective devices on the compressor (relief valves, vibration shutdowns, temperature trips) get no failure-finding tasks because their hidden function was never analyzed.
Mistake 5: Ignoring the proactive task hierarchy. The engineer recommends “monthly inspection” for most failure modes without evaluating whether on-condition tasks, scheduled restoration, or scheduled discard would be more appropriate. The result is generic task recommendations that don’t match the underlying failure characteristics.
The Audit Result: The “RCM analysis” passes the audit because a document exists that includes the seven question categories. But the document does not satisfy SAE JA1011 conformance criteria. The maintenance program built from the analysis includes both unnecessary PMs (operational tasks for failure modes that warrant run-to-failure) and missing tasks (no failure-finding for protective devices). The analysis produces worse maintenance outcomes than the original PM program it replaced.
This pattern – RCM-as-deliverable rather than RCM-as-analysis – is one of the most common failure modes of the methodology itself. SAE JA1011 was specifically created in response to this pattern, and its conformance criteria are the recognized test for whether an RCM implementation is genuine.
RCM Variants: Classical, RCM2, RCM3, MSG-3, Streamlined, PMO
Multiple methodologies share the RCM name with significant variation in rigor and applicability.
Classical RCM refers to the original Nowlan-Heap methodology documented in the 1978 report. The methodology was designed for commercial aviation applications and remains the reference for what RCM means at its most rigorous. Classical RCM is widely associated with Anthony “Mac” Smith’s adaptation for industrial applications.
RCM2 (also written RCMII) is John Moubray’s industrial adaptation, published in 1990 and refined through the Aladon Network. RCM2 modified the original methodology to be more applicable to industries beyond aviation, added explicit treatment of environmental consequences alongside safety consequences, and refined the decision logic. RCM2 is the most widely deployed RCM methodology in industrial applications globally and was a primary input to SAE JA1011. Moubray’s book “Reliability-Centered Maintenance” (second edition 1997) remains the most widely cited industrial RCM reference.
RCM3 is the Aladon Network’s continuation of RCM2 after Moubray’s death in 2004, developed by Marius Basson. RCM3 brings the methodology in line with fourth-generation asset management expectations and integrates with international asset management and risk management standards including ISO 55000 and ISO 31000.
MSG-3 (Maintenance Steering Group, 3rd revision) is the aviation-specific successor to MSG-1 and MSG-2, used for commercial aircraft maintenance program development by manufacturers and operators. MSG-3 shares heritage with RCM but is technically distinct, applying specifically to commercial aviation rather than general industrial assets. The U.S. Naval aviation methodology documented in NAVAIR 00-25-403 is similarly a specialized RCM application.
Streamlined RCM refers to abbreviated approaches that skip some classical RCM steps to reduce time and resource investment. Many streamlined methodologies do not satisfy SAE JA1011 criteria and may produce inferior results. SAE JA1011 conformance is the recognized test – methodologies that skip questions or answer them out of sequence are not RCM by the standard’s definition, regardless of marketing claims.
PMO (Preventive Maintenance Optimization) is a related but distinct methodology designed for assets that already have maintenance programs in place. PMO works backward from existing PM tasks rather than forward from functions to failure modes to tasks. Steve Turner’s PMO2000 is the most widely referenced PMO methodology, with substantial published comparisons against RCM. PMO can deliver similar maintenance program outcomes to RCM at roughly one-sixth the time and cost for mature assets, though it cannot identify failure modes that the existing PM plan misses entirely.
Industry Context: Where RCM Is and Is Not Used
RCM adoption varies substantially across industries, and the variation reflects honest assessments of where the methodology delivers value relative to alternatives.
Commercial aviation (origin industry) uses MSG-3 for commercial aircraft maintenance program development. The discipline is enforced by FAA regulations and customer airline requirements. Aviation maintenance program development is the most rigorous RCM-derived application in any industry.
Nuclear power deploys RCM widely, often with regulatory backing. The U.S. Nuclear Regulatory Commission has acknowledged RCM as a basis for maintenance program optimization, and many U.S. nuclear plants use RCM or RCM-derived methodologies. The combination of high consequences, high asset value, and regulatory scrutiny makes nuclear an environment where the resource investment in classical RCM is justified.
Military and defense (US Navy NAVAIR) uses RCM via NAVAIR 00-25-403 for naval aviation, with FMECA paired into the analysis. Defense applications generally have the resource budget for classical RCM and the consequence levels that justify it.
Oil and gas uses RCM for offshore platforms and onshore process facilities, often paired with Risk-Based Inspection (RBI) for static equipment. The industry’s combination of safety consequences, environmental consequences, and high asset value makes RCM economically justified for major equipment, though PMO is also widely deployed for established facilities.
Mining applies RCM selectively to major mobile equipment fleets where downtime costs are extreme. Haul trucks, shovels, and processing equipment justify RCM analysis; smaller equipment typically does not.
General manufacturing uses RCM less commonly than aviation, nuclear, or oil and gas. The cost-benefit calculation often favors PMO for mature operations or simpler maintenance optimization approaches for smaller operations. RCM in general manufacturing is most common at automotive OEMs, large-scale chemical and pharmaceutical operations, and high-value process operations like semiconductor fabs.
The Honest Critique: When RCM Is and Is Not Worth Doing
RCM is a powerful methodology when applied rigorously to appropriate assets. It is also widely misapplied, often producing worse outcomes than the maintenance programs it replaces. A few honest assessments worth flagging.
Classical RCM is resource-intensive. A complete RCM analysis for a single critical asset typically requires 40 to 200 hours of cross-functional team time. A facility-wide RCM program covering hundreds of assets can require thousands of hours and take months to years to complete. Operations that commit to RCM without realistic resource budgets typically produce incomplete analyses that satisfy neither SAE JA1011 nor practical maintenance objectives.
Most “RCM” implementations don’t satisfy SAE JA1011. The SAE standard exists specifically because so many methodologies marketed as RCM don’t satisfy the original methodology’s criteria. Operations evaluating RCM software, consultants, or training should verify SAE JA1011 conformance explicitly rather than accepting marketing claims. The differences between conforming and non-conforming methodologies are operationally consequential.
PMO often delivers most of the value at a fraction of the cost. For mature operations with existing PM programs, PMO can produce similar maintenance optimization outcomes at roughly one-sixth the time and cost of classical RCM. The fundamental limitation of PMO – that it can only optimize failure modes already addressed by the existing PM plan – matters less for mature operations where the existing PM plan addresses most relevant failure modes. PMO is the right starting point for most operations with established maintenance programs.
RCM is the right tool for specific situations. Green-field maintenance program development for new equipment or new facilities. Critical equipment where coverage gaps would be dangerous (typically safety-critical or high-consequence assets). Operations where the existing PM plan is fundamentally broken and PMO cannot rescue it. Major equipment where the resource investment in classical RCM is economically justified by the consequences of inadequate maintenance.
RCM is the wrong tool for many situations where it gets deployed. Operations attempting RCM on every asset, including low-consequence assets where run-to-failure would be the RCM-defensible policy. Mid-market manufacturers without the resources for rigorous cross-functional analysis. Operations with mature PM programs where PMO would deliver similar value faster and cheaper. Compliance-driven RCM where the goal is producing a deliverable rather than improving maintenance outcomes.
RCM is “thoughtware, not software.” John Moubray’s observation captures an important truth. Software platforms can support RCM analysis but cannot perform it. The cross-functional analysis, the consequence classification, the task evaluation – these require human judgment that no software replaces. Operations that buy RCM software expecting it to produce RCM outcomes typically discover that the software produces structured documents that look like RCM but lack the analytical substance.
RCM and Related Methods
RCM fits within a broader reliability and maintenance methodology ecosystem.
FMEA (Failure Mode and Effects Analysis) is the analytical engine for RCM Question 3 (failure mode identification). RCM integrates FMEA into a broader decision framework, while FMEA without RCM produces failure mode lists without maintenance strategy decisions. Our FMEA methodology guide covers the FMEA component in detail.
FMECA (Failure Mode, Effects, and Criticality Analysis) extends FMEA with quantitative criticality analysis. FMECA is used in classical RCM applications, particularly in aerospace and military, where quantitative reliability data supports more rigorous task selection.
P-F Curve and Condition-Based Maintenance provides the analytical basis for on-condition tasks (Question 6). The P-F interval — the time between potential failure detection and functional failure – determines whether on-condition tasks are technically feasible.
Weibull Analysis characterizes failure distributions over time and supports decisions about whether scheduled restoration or scheduled discard tasks are technically feasible. The Weibull beta parameter indicates whether equipment is in infant mortality (beta less than 1, where age-based tasks are inappropriate), random failure (beta equal to 1, where MTBF applies cleanly), or wear-out (beta greater than 1, where time-based tasks may be appropriate).
Risk-Based Inspection (RBI) applies risk-based methodology to inspection programs for static equipment. RBI is widely used in oil and gas and chemical industries for pressure vessels, piping, and storage tanks. RBI and RCM are complementary – RBI handles inspection programs for static equipment, RCM handles maintenance programs for rotating and dynamic equipment.
FRACAS (Failure Reporting, Analysis, and Corrective Action System) captures actual field failures and feeds them back into RCM analyses. FRACAS data improves RCM accuracy by replacing subjective failure mode estimates with actual operational failure rates.
HAZOP (Hazard and Operability Study) applies to process operations and identifies deviations from design intent. HAZOP and RCM are complementary in process industries – HAZOP focuses on operational deviations, RCM focuses on equipment maintenance.
Common Mistakes in RCM
The methodology is rigorous. The mistakes are systematic. Seven common errors that undermine RCM analyses:
1. Single-person analysis. Cross-functional analysis is required by SAE JA1011 conformance. Single-person RCM systematically misses failure modes that other perspectives would identify.
2. Skipping or minimizing function definition. Function definition is the foundation of the analysis. Operations that treat function as obvious and skip rigorous definition produce incomplete failure mode lists.
3. Conflating failure modes with effects or causes. Each is a distinct concept and must be analyzed separately. Conflation produces analyses that cannot drive meaningful task selection.
4. Treating all failures as having operational consequences. The four consequence categories drive different task selection. Defaulting all evident failures to operational consequences misses the safety/environmental and non-operational distinctions that should change task choices.
5. Ignoring hidden failures. Hidden failures require failure-finding tasks. Operations that don’t explicitly identify hidden failures (typically associated with protective devices) leave critical safety risks unmanaged.
6. Skipping the proactive task hierarchy. On-condition before restoration before discard is the order of preference for technical and economic reasons. Operations that default to scheduled restoration without evaluating on-condition typically miss better task options.
7. RCM-as-deliverable rather than RCM-as-analysis. Compliance-driven RCM produces documents that look like RCM but don’t satisfy SAE JA1011 conformance and don’t improve maintenance outcomes. SAE JA1011 was created specifically because of this pattern.
Frequently Asked Questions
What is RCM?
RCM (Reliability-Centered Maintenance) is a structured methodology for determining the optimal maintenance strategy for each asset based on its function, failure modes, failure consequences, and operating context. The methodology was developed by United Airlines in the 1960s, formalized by Stanley Nowlan and Howard Heap in their 1978 report, and adapted for industrial use by John Moubray in the 1980s. RCM is structured around seven questions defined in SAE Standard JA1011.
What are the seven RCM questions?
The seven questions specified by SAE JA1011 are: 1) What are the functions and associated desired standards of performance of the asset in its present operating context? 2) In what ways can it fail to fulfill its functions? 3) What causes each functional failure? 4) What happens when each failure occurs? 5) In what way does each failure matter? 6) What should be done to predict or prevent each failure? 7) What should be done if a suitable proactive task cannot be found?
What are the four RCM consequence categories?
RCM2 classifies failure consequences into four categories: hidden failure consequences (failures not evident under normal conditions, typically protective devices), safety and environmental consequences (failures that could kill, injure, or breach environmental standards), operational consequences (failures affecting production, quality, or operating costs), and non-operational consequences (failures affecting only direct repair cost). The consequence category drives task selection.
What is the difference between RCM and PMO?
RCM works forward from functions through failure modes to maintenance tasks, designed for green-field maintenance program development. PMO (Preventive Maintenance Optimization) works backward from existing PM tasks, designed for assets that already have maintenance programs. PMO is meaningfully faster and less resource-intensive than RCM for mature assets, often producing similar results in roughly one-sixth the time and cost. PMO’s limitation is that it can only optimize failure modes already addressed by the existing PM plan; RCM identifies failure modes the existing plan misses entirely.
What is the difference between RCM and RCM2?
RCM refers broadly to the methodology developed by Nowlan and Heap. RCM2 (also written RCMII) is John Moubray’s industrial adaptation, published in 1990 and refined through the Aladon Network. RCM2 modified the original methodology for industrial applications, added explicit treatment of environmental consequences, and refined the decision logic. RCM2 is the most widely deployed RCM methodology globally and was a primary input to SAE JA1011. After Moubray’s death in 2004, the Aladon Network developed RCM3 as a continuation.
What is SAE JA1011?
SAE JA1011 is the technical standard “Evaluation Criteria for Reliability-Centered Maintenance (RCM) Processes,” first published August 1999 in response to widespread use of “RCM” for methodologies that deviated from the original methodology. The standard establishes the minimum criteria that any process must satisfy to be called RCM. Current revision is JA1011_202411 (November 2024). The companion standard JA1012 provides implementation guidance.
What are the proactive task categories in RCM?
Three proactive task categories are evaluated in order of preference: on-condition tasks (predictive/condition-based maintenance), scheduled restoration tasks (time-based overhaul), and scheduled discard tasks (time-based replacement). When no proactive task is technically feasible or worth doing, RCM falls back to default actions: failure-finding for hidden failures, redesign for safety or environmental consequences, and run-to-failure for non-operational consequences.
How long does an RCM analysis take?
Classical RCM is resource-intensive. A complete RCM analysis for a single critical asset typically requires 40 to 200 hours of cross-functional team time. A facility-wide RCM program covering hundreds of assets can require thousands of hours and take months to years. The resource intensity is one of the most common criticisms of classical RCM and one of the primary reasons PMO and streamlined RCM variants exist.
Related Guides
- How to Perform FMEA: Methodology and Worked Examples
- How to Calculate MTBF and MTTR: Methodology and Worked Examples
- How to Calculate OEE: Methodology and Worked Examples
- Best CMMS Software 2026: Independent Comparison
- Best Asset Performance Management Software 2026
- APM vs CMMS: What’s the Difference, and Which One Do You Need?
Sources
- SAE JA1011_202411 – Evaluation Criteria for Reliability-Centered Maintenance (RCM) Processes (November 2024 revision)
- SAE JA1012 – A Guide to the Reliability-Centered Maintenance (RCM) Standard
- Nowlan, F. Stanley, and Howard F. Heap. “Reliability-Centered Maintenance.” U.S. Department of Defense, 1978. Report Number AD-A066579.
- Moubray, John. “Reliability-Centered Maintenance” (Second Edition). Industrial Press, 1997.
- NAVAIR 00-25-403 – Guidelines for the Naval Aviation Reliability-Centered Maintenance Process
- MIL-STD-2173(AS) – Reliability-Centered Maintenance Requirements for Naval Aircraft, Weapons Systems and Support Equipment
- NAVSEA Reliability Centered Maintenance (RCM) Handbook S9081-AB-GIB-010
- IEC 60300-3-11 – Application Guide: Reliability Centred Maintenance
- Smith, Anthony M. “Reliability-Centered Maintenance” (Classical RCM industrial adaptation)
- Turner, Steve. PMO2000 methodology documentation, OMCS International
- SMRP Best Practices – Society for Maintenance and Reliability Professionals
- Reliable Magazine independent editorial analysis
Last updated: May 2, 2026. This guide is editorial analysis by Reliable Magazine.







