TL;DR: Preventive maintenance (PM) is a proactive maintenance strategy where work is performed at predetermined time or usage intervals to prevent failure. PM is one of several proactive strategies – alongside condition-based maintenance (CBM) and predictive maintenance (PdM) – that organizations use to manage equipment reliability. The technically precise definition matters because PM, CBM, and PdM have different trigger logic, infrastructure requirements, and operational characteristics. Building a PM program is a structured eight-step process: inventory assets, rank by criticality, select strategy per tier, define tasks and frequencies, deploy in CMMS, train operators and technicians, track KPIs, and review annually. PM programs fail more often than they succeed, and the failure modes are predictable – most fail from missing asset criticality foundations, frequency-without-data assumptions, iatrogenic over-maintenance, and treating PM as a compliance activity rather than a reliability program. This guide covers the methodology with worked examples, SMRP and ISO 55000 framework alignment, modern CMMS integration, and the honest middle ground that vendor-published guides systematically avoid.
What Preventive Maintenance Actually Is
Preventive maintenance (PM) is a proactive maintenance strategy where work is scheduled at predetermined time or usage intervals to prevent equipment failure. PM tasks include inspection, lubrication, calibration, cleaning, adjustment, and component replacement. The two PM trigger types are time-based (calendar intervals) and usage-based (operating hours, cycles, miles). Both perform work regardless of actual equipment condition – which is what distinguishes PM from condition-based and predictive maintenance strategies that trigger on measured condition.
The Society for Maintenance and Reliability Professionals (SMRP) addresses preventive maintenance under the Equipment Reliability pillar of its Body of Knowledge – one of five pillars defining the M&R discipline (Business and Management, Manufacturing Process Reliability, Equipment Reliability, Organization and Leadership, and Work Management). ISO 55000, the international standard for asset management, requires a documented maintenance program as part of asset management plan compliance. SAE JA1011 – the international standard for Reliability-Centered Maintenance — provides the formal framework that determines which maintenance strategy (including PM) is appropriate for each failure mode.
The strategic case for PM is well-established in reliability engineering literature. Reactive maintenance produces unpredictable cost, unplanned downtime, and emergency parts and labor with premium pricing. PM produces predictable cost, scheduled downtime, and known parts and labor requirements. Mature operations target a high ratio of planned to unplanned work – common world-class targets are around 80/20, with reliability leaders reaching 90/10. The specific magnitudes of cost and downtime improvement depend on baseline maturity, asset criticality profile, and operating context, but the directional benefits are consistent across reliability engineering practice.
The tactical case is harder. Building a PM program that delivers these outcomes requires structured methodology, sustained management commitment, integrated CMMS infrastructure, and continuous optimization over multi-year cycles. PM programs fail more often than they succeed, and the failure modes are predictable. This guide covers both the methodology and the failure modes, because acknowledging the latter is what differentiates serious reliability content from vendor-published content that systematically avoids the topics that conflict with software-as-the-answer narratives.
How Preventive Maintenance Fits in the Maintenance Strategy Stack
PM is one of several maintenance strategies. The strategies are organized below in the framework that aligns with SAE JA1011 RCM categorization and SMRP-aligned reliability engineering practice. This framing – treating PM, CBM, and PdM as parallel proactive strategies rather than as types of PM – is the convention used in formal reliability engineering. Some sources, particularly CMMS vendor publications, group all four under a broad “preventive” umbrella; the parallel-strategies framing used here is more technically precise and aligns with how reliability engineers select among strategies in practice.
Reactive maintenance (Run-to-Failure). No maintenance is performed until equipment fails, then the asset is repaired or replaced. RCM treats Run-to-Failure as a deliberate strategy rather than a default – appropriate when failure consequences are minor and the cost of preventive activity exceeds the cost of failure. Typical examples include non-critical light bulbs, low-cost redundant assets, and consumables. Programs heavy in unintentional run-to-failure (failure occurring on assets that should have been on PM) indicate program immaturity rather than deliberate strategy.
Corrective maintenance. Repairs equipment after failure, typically including some level of failure analysis and root cause investigation. Corrective maintenance is the response when other strategies miss a failure, and a residual amount is unavoidable in any program.
Preventive maintenance (PM). Performs scheduled work at fixed time or usage intervals before failure occurs. The strategy this guide covers in depth. Appropriate for assets where failure patterns are predictable enough that scheduled intervention is cost-effective. PM has two sub-types: time-based and usage-based, both characterized by scheduling that ignores actual current condition.
Condition-based maintenance (CBM). Triggers tasks when measured equipment condition reaches an action threshold rather than at a scheduled time or usage interval. Requires sensor or inspection data infrastructure (vibration accelerometers, oil sample taps, thermography access points, ultrasonic test points, process instruments). CBM aligns maintenance precisely with equipment condition.
Predictive maintenance (PdM). Extends CBM with analytics, historical pattern recognition, and increasingly machine learning to forecast failure timing. PdM triggers maintenance at the predicted optimal point — late enough to maximize component life but early enough to prevent failure. Requires the sensor infrastructure of CBM plus analytics capability.
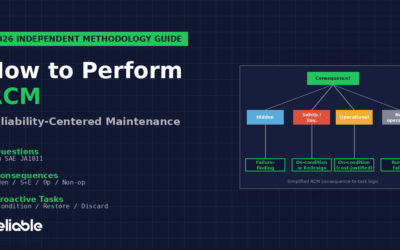
Reliability-Centered Maintenance (RCM). A methodology – not a maintenance type – for determining which strategy applies to each failure mode of a critical asset. SAE JA1011 defines RCM as a process that answers seven questions and classifies failure consequences into four categories (hidden, safety/environmental, operational, non-operational), then selects from five failure management policies including scheduled restoration, scheduled discard, condition-based tasks, failure-finding tasks, and run-to-failure. RCM produces the strategy mix that PM, CBM, and PdM execute. See our RCM methodology guide for the full framework.
Most mature operations use a strategy mix determined by asset criticality. Critical assets receive condition-based or predictive coverage where the avoided failure cost justifies the monitoring infrastructure. Important assets receive time-based or usage-based PM at intervals derived from OEM recommendations adjusted for operating context. Non-critical assets run to failure or receive minimal PM. Asset criticality analysis (ACA) is the methodology that determines the mix – see our Asset Criticality Analysis guide.

The Two Types of Preventive Maintenance
PM is classified by what triggers the maintenance task. Both PM types schedule work in advance regardless of current equipment condition – which is the characteristic that distinguishes PM from CBM and PdM.

Time-Based Maintenance (Calendar-Based)
Tasks scheduled at fixed calendar intervals regardless of equipment use. Examples: replace HVAC filters every three months, conduct boiler inspection every six months, replace cooling tower fill every two years. Time-based PM is the simplest to schedule and execute, requires no condition monitoring infrastructure, and provides predictable budgeting and resource planning.
The disadvantage is that time-based schedules ignore actual equipment condition and operating context. Equipment in good condition gets unnecessary maintenance; equipment degrading faster than the schedule anticipates may fail before the next scheduled PM. Time-based PM is appropriate for assets with predictable wear patterns operating in consistent contexts, regulatory-mandated maintenance schedules, and non-critical assets where the simplicity advantage outweighs the precision disadvantage.
Usage-Based Maintenance
Tasks scheduled based on operating data – runtime hours, production cycles, miles traveled, throughput volume. Examples: service forklifts every 200 operating hours, change diesel engine oil every 250 hours, inspect press tooling every 100,000 cycles. Usage-based PM aligns better with actual equipment wear than calendar-based scheduling because it accounts for variable utilization.
The disadvantage is that usage-based PM still ignores actual equipment condition – heavily-loaded equipment may degrade faster than runtime hours suggest, and lightly-loaded equipment may run longer than the schedule allows. Usage-based PM is appropriate for assets with strong correlation between usage and wear, mobile and fleet equipment with variable utilization, and assets where runtime data is reliably captured (typically through CMMS integration with control systems).
Related Proactive Maintenance Strategies (CBM and PdM)
Condition-based maintenance and predictive maintenance are not types of preventive maintenance. They are related proactive strategies that share PM’s goal of intervening before failure but differ fundamentally in trigger logic. Including them here clarifies how they relate to PM in a complete maintenance strategy mix.
Condition-Based Maintenance (CBM)
Tasks triggered when measured equipment condition reaches an action threshold. Examples: replace bearing when vibration exceeds a defined velocity limit, change lubricant when oil analysis shows ISO cleanliness exceeding a target, replace heat exchanger tubes when ultrasonic thickness measurement shows wall loss exceeding a defined percentage. CBM aligns maintenance precisely with equipment condition, eliminating both over-maintenance and under-maintenance.
The infrastructure requirement is the trade-off. CBM requires sensors, data acquisition systems, baseline measurements, alarm threshold configuration, and trained personnel to interpret results. The investment is justified for critical assets where avoided failure cost is significant, but rarely justified for non-critical assets where time-based PM produces adequate outcomes at lower cost.
Predictive Maintenance (PdM)
An advanced form of condition-based maintenance that uses analytics, machine learning, and pattern recognition to forecast failure timing. Instead of triggering work when condition reaches an alarm threshold (CBM), PdM triggers work at the predicted optimal point – late enough to maximize component life but early enough to prevent failure. Examples: machine learning models that detect bearing degradation patterns weeks before vibration alarm thresholds trigger, oil analysis trending that forecasts gear tooth wear to specific replacement timing, thermal imaging analysis that identifies developing electrical connection failures before they become visible to traditional thermography.
PdM extends CBM with predictive analytics. The infrastructure requirements exceed CBM by adding analytics platforms, historical data foundations, and algorithm development or vendor partnerships. PdM is appropriate for the highest-criticality assets where unplanned downtime cost is large enough to justify the analytics investment.
For platform comparison of PdM and broader Asset Performance Management software, see our APM platform comparison guide.
The Eight-Step Methodology for Building a PM Program
Building a PM program from scratch – or rebuilding one that has deteriorated – is a structured methodology. The steps are sequential, and skipping or compressing steps is the most common cause of program failure.

Step 1: Inventory Your Assets
Build a complete asset register documenting every maintainable item across the facility. Each asset record should capture make, model, serial number, location, installation date, operating context, OEM documentation links, and parent-child relationships in the asset hierarchy.
ISO 14224 provides a canonical hierarchy structure used widely in process industries (the standard’s primary scope is petroleum, petrochemical, and natural gas, but the hierarchy framework has been adapted across other industries). Most PM programs analyze at the maintainable item level — the level at which work orders are written and PM tasks are scheduled. Analyzing too high (system level) loses the granularity needed for task-specific scheduling. Analyzing too low (component level) generates too many records to manage effectively.
The asset inventory is the foundation. Programs without a clean asset inventory cannot build PM schedules that reliably cover all critical equipment, and gaps surface months later as missed PMs accumulate. Most operations discover during this step that their existing asset records require substantive cleanup before PM scheduling can begin.
Step 2: Rank Assets by Criticality
Apply asset criticality analysis to rank every asset by the consequence of failure and the likelihood of failure. The standard formula is:
Criticality = Consequence × Likelihood
Consequence is the weighted sum of severity scores across multiple categories – typically Safety, Environment, Production, Quality, Maintenance Cost, and Customer Impact, with Regulatory Compliance added in regulated industries. Likelihood is the probability of failure within the analysis time horizon. The result is a criticality score that drives tier classification.
Standard tier classification using Pareto-style cutoffs:
- Tier 1 — Critical (typically 10-20% of assets): Warrant condition-based, predictive, or rigorous time-based coverage with frequent review and dedicated spare parts strategy
- Tier 2 — Important (typically 30-40% of assets): Receive scheduled time-based or usage-based PMs at OEM-recommended intervals adjusted for operating context, with annual review
- Tier 3 — Non-Critical (typically 50-60% of assets): Run-to-failure or minimal PM with corrective response triggered by failures
The full Asset Criticality Analysis methodology – including weighting factors, severity scales, and worked examples – is covered in our Asset Criticality Analysis guide.
This step is non-optional. PM programs built without criticality analysis treat all assets as equally important, which over-maintains non-critical assets and under-maintains critical assets. The result is high PM cost without proportional reliability benefit.
Step 3: Select the Maintenance Strategy for Each Tier
For each criticality tier, determine the appropriate maintenance strategy. The four proactive strategies – PM (time-based and usage-based), CBM, and PdM – are not interchangeable, and the selection materially affects program cost and effectiveness.
For Critical assets, RCM analysis per SAE JA1011 is the formal methodology for strategy selection. The RCM process answers seven questions about each asset’s functions, failure modes, failure effects, failure consequences, and appropriate management policies. Operations without resources for full RCM on every Critical asset typically use streamlined RCM or RCM-Lite approaches that capture the essential analysis without the full SAE JA1011 documentation rigor.
For Important assets, strategy selection typically follows simpler rules: time-based or usage-based PM at OEM-recommended intervals adjusted for operating context, with CBM added for assets where condition monitoring infrastructure is already deployed for adjacent Critical assets.
For Non-Critical assets, strategy selection typically defaults to run-to-failure with corrective response, with minimal PM only where regulatory or OEM warranty requirements mandate it.
The strategy selection step is where many PM programs go wrong. Programs that apply uniform PM to all assets regardless of criticality produce both over-maintenance of non-critical assets (waste) and under-maintenance of critical assets (where CBM or PdM would be more effective). The strategy mix is the deliverable, not just the asset list.
Step 4: Define PM Tasks and Set Frequencies
For assets receiving preventive maintenance, define the specific tasks and frequencies. Each task specification must capture:
- What the task does (specific procedure, components addressed)
- How to perform it (techniques, tools, materials, safety requirements including LOTO)
- Who performs it (operator versus technician, skill level required)
- Required parts (with CMMS reservation logic)
- Required tools and equipment
- Expected duration (for resource planning)
- Acceptance criteria (what good looks like, with photos where helpful)
- Documentation requirements (what gets captured in CMMS)
Joel Levitt’s framework for PM task design (in Complete Guide to Preventive and Predictive Maintenance) requires every task to be technically feasible (the task addresses an actual failure mode), worth doing (the cost of the task is less than the cost it prevents), and supported by data (failure history or reliability analysis justifies the task and frequency).
Frequency-setting inputs:
- OEM recommendations – the starting point for assets without operational history. OEM intervals are typically conservative and may need adjustment based on actual operating context.
- Historical failure data – three to five years of CMMS failure history reveals actual MTBF for the asset class, which directly informs PM frequency.
- Operating context – temperature, vibration, contamination, duty cycle, and process severity all affect optimal PM frequency.
- Regulatory requirements – minimum intervals required by FDA, OSHA, NERC, FSMA, or similar regulatory frameworks.
The most common frequency-setting error is using OEM recommendations without adjustment for operating context. The same pump model in clean cooling water service and in slurry service will have substantially different optimal PM intervals despite identical OEM defaults. Programs that establish frequency-setting guidelines based on operating context categories (severe, normal, mild) and apply them systematically produce substantially better outcomes than programs using OEM defaults uniformly.
Step 5: Deploy in CMMS
Configure PM schedules, task lists, parts requirements, and labor estimates in the CMMS. The CMMS is the operational backbone – without integrated CMMS support, PM programs at meaningful scale fail to execute reliably.
CMMS configuration includes:
- Asset records with the full hierarchy, criticality classification, and OEM documentation links
- PM master schedules with trigger logic (time, usage, condition), task assignment, parts reservation, and labor allocation
- Task instructions accessible to technicians at the equipment via mobile CMMS apps
- Acceptance criteria captured as required fields on PM completion
- Compliance tracking with PM compliance rate, schedule adherence, and audit-ready reporting
- Integration with parts inventory, procurement, and reliability analytics
Modern CMMS platforms support time-based and usage-based PM triggers natively. Most also support condition-based work order generation through integration with sensor data, condition monitoring routes, or process historians (OSIsoft PI, AVEVA PI System, Honeywell PHD). Mobile CMMS apps enable technicians to receive work orders, capture execution data, and photograph defects directly at the equipment. For platform comparison, see our CMMS comparison guide.
CMMS without strong PM functionality forces programs into spreadsheet workarounds that fail to scale beyond small operations. Operations attempting PM programs at facility scale without integrated CMMS infrastructure consistently produce inconsistent execution, missed PMs, and audit findings.
Step 6: Train Operators and Technicians
Train technicians on PM task execution including standardized procedures, quality acceptance criteria, and abnormality identification beyond the task scope. Training depth must match task complexity. Programs that compress training routinely produce inconsistent execution and missed abnormalities.
Training scope:
- Technician training on PM task execution, equipment fundamentals (mechanical, electrical, instrumentation), troubleshooting techniques, and quality acceptance criteria
- Operator training on operator-executable PMs (cleaning, lubrication, basic inspection), abnormality identification, and CMMS work request submission
- Planner training on PM scheduling, parts coordination, labor planning, and continuous improvement methodology
- Reliability engineer training on PM optimization techniques, failure analysis, and program performance evaluation
Skills certification formalizes capability levels and creates clear development paths. SMRP offers two certification programs relevant here: the Certified Maintenance and Reliability Professional (CMRP) for engineering and management roles, and the Certified Maintenance and Reliability Technician (CMRT) for hands-on technicians. Both are accredited by ANSI under ISO/IEC 17024 and provide structured skill validation that benefits PM program consistency.
Training integration with autonomous maintenance is the modern best practice. Operator-executable PMs typically deploy within an autonomous maintenance program rather than as a separate scheme – see our Autonomous Maintenance guide for the JIPM seven-step framework that pairs naturally with PM program deployment.
Step 7: Track KPIs and Optimize
Track program performance through a focused set of KPIs. The goal is continuous optimization based on data rather than activity tracking divorced from outcomes. SMRP publishes standardized definitions for these metrics in its Best Practices guide – using SMRP definitions ensures consistent measurement and enables benchmarking against industry data.
Primary PM program KPIs:
- PM Compliance Rate – percentage of PM tasks completed within the scheduled window. SMRP defines a target band depending on operation type. Below 70% indicates program execution problems.
- Mean Time Between Failures (MTBF) – total operational time divided by number of failures. Trending upward indicates effective PM. See our MTBF/MTTR methodology guide.
- Mean Time To Repair (MTTR) – average time to restore function after failure. Trending downward indicates effective response and parts availability.
- Planned vs. Unplanned Work Ratio – common world-class targets are around 80/20, with reliability leaders reaching 90/10. Below 70% planned indicates reactive-heavy operations needing PM program investment.
- Maintenance Cost as a Percentage of Replacement Asset Value (RAV) – total maintenance cost divided by RAV, expressed annually. SMRP publishes industry benchmarks. Lower percentages with stable or improving reliability indicate program maturity.
- Overall Equipment Effectiveness (OEE) – the primary success metric for plants where PM programs target availability, performance, and quality losses. See our OEE methodology guide.
Secondary KPIs include backlog age, schedule compliance, wrench time, PM yield (percentage of PMs that identify abnormalities requiring follow-up), and condition monitoring trend stability.
Programs that track activity metrics (PM completions, work orders processed) without tracking outcome metrics (reliability, cost, OEE) typically deteriorate because activity becomes the goal. PM compliance rate of 95% with declining MTBF indicates the wrong PMs are being executed, not that the program is healthy. Activity metrics measure execution; outcome metrics measure effectiveness.
Step 8: Review and Refine Annually
Conduct annual program reviews that examine PM effectiveness against reliability outcomes, identify over-maintained and under-maintained assets, retire ineffective tasks, and incorporate lessons learned from failures and audits.
Review activities:
- PM effectiveness analysis – comparing PM frequency and execution against actual failure data to identify tasks that are not preventing failures
- Frequency adjustment – increasing frequency on assets with declining MTBF, decreasing frequency on assets with no failure history despite adequate inspection
- Task retirement – eliminating PMs that consume resources without preventing failures
- Task addition – adding PMs for failure modes that have surfaced since the last review
- Strategy reclassification – moving assets between time-based PM, CBM, and PdM as condition monitoring infrastructure expands or contracts
- Criticality reclassification – updating asset criticality scores based on operational changes
- CMMS data quality audit – verifying asset records, task instructions, and parts data remain accurate
Critical assets should be reviewed more frequently than annually – typically quarterly. ISO 55000-aligned programs document the review cycle in the asset management plan as a formal requirement.
Static PM programs deteriorate in usefulness as operations evolve, equipment ages, and operating context changes. Programs without review cycles typically produce strong initial results that erode over multi-year periods as the supporting data becomes stale.
Worked Example: PM Program for a Centrifugal Pump Population
The methodology applies the same way regardless of equipment class, but specifics matter for understanding. Here is what each step looks like applied to a centrifugal pump population in a process operation.
Step 1: Inventory. The asset inventory captures the full pump population across the facility, organized in ISO 14224 hierarchy with each pump linked to its parent process unit, OEM documentation (Goulds, Sulzer, Flowserve, ITT, KSB), and current operating context (service type, fluid handled, operating hours).
Step 2: Criticality. Asset criticality analysis tiers the pump population. A typical distribution: Tier 1 includes primary process pumps without redundancy where failure shuts down the unit. Tier 2 includes process pumps with redundancy or utility pumps where failure causes degraded operation. Tier 3 includes sump pumps, drain pumps, and similar low-consequence services.
Step 3: Strategy Selection.
Tier 1 pumps receive condition-based maintenance: continuous online vibration monitoring on the highest-criticality units, route-based portable vibration analysis on the others, oil analysis programs, and time-based mechanical seal inspection at OEM intervals adjusted for service severity. Run-to-failure is not appropriate for Tier 1 pumps even when redundancy exists, because parallel failures during single-pump operation defeat the redundancy logic.
Tier 2 pumps receive time-based and usage-based PM: monthly visual inspection (operator), quarterly route-based vibration analysis (technician), semi-annual oil change at usage-based trigger or time-based whichever comes first, annual mechanical seal inspection, and bearing replacement at OEM-recommended intervals adjusted for operating context.
Tier 3 pumps receive run-to-failure with corrective response. Minimal PM (quarterly visual inspection, annual lubrication) is performed only where required by regulation or OEM warranty.
Step 4: Tasks and Frequencies. Frequencies are set using historical failure data combined with OEM recommendations and operating context. Tier 1 pumps in clean service receive less frequent vibration analysis than Tier 1 pumps in slurry service despite identical criticality classification. The frequency variation reflects operating severity – a methodology adjustment that uniform OEM-recommended frequencies would miss.
Step 5: CMMS Deployment. The CMMS is configured with PM master schedules for each pump tier. Time-based PMs trigger at calendar intervals. Usage-based PMs trigger at runtime hours captured from process control system integration. Condition-based work orders trigger when vibration analysis routes upload data exceeding configured thresholds. Mobile CMMS apps deliver task instructions, parts lists, and acceptance criteria to technicians at the pump.
Step 6: Training. Operators receive training on weekly visual inspection technique, abnormality identification, and CMMS work request submission. Technicians receive training on vibration analysis interpretation (typically Vibration Analyst Category I and II per ISO 18436-2), oil analysis program management, mechanical seal inspection, and bearing replacement procedures. Reliability engineering staff receive training on PM optimization techniques applied to the pump population.
Step 7: KPIs. The pump program tracks PM compliance rate, pump fleet MTBF, unplanned-to-planned ratio, and pump-related production loss. Trends matter more than absolute numbers – a fleet MTBF improving from 14,000 to 18,000 operating hours over 24 months demonstrates program effectiveness; a stable but high MTBF that has not been validated against the broader fleet may mask under-counting of failures.
Step 8: Review. Annual review identifies assets where vibration analysis has produced no actionable findings over multiple cycles, suggesting frequency reduction is appropriate. Pumps that have failed multiple times are reclassified to higher tiers with appropriate strategy changes. Newly-installed pumps receive criticality classification based on the units they support. Frequencies are adjusted, tasks are added or retired, and the program continues evolving.
Modern PM: CMMS Integration, Mobile Execution, and Condition Monitoring
Modern PM programs integrate with digital infrastructure that did not exist when the foundational PM methodology was codified. The integration changes how programs are deployed in practice.
CMMS as operational backbone. Modern CMMS platforms automate PM scheduling, task assignment, parts reservation, compliance tracking, and reporting. Mobile CMMS apps enable technicians to receive work orders, capture execution data, photograph defects, and submit work requests directly at the equipment. Major platforms – IBM Maximo, SAP S/4HANA Asset Management, eMaint, MaintainX, Limble, Fiix, UpKeep – support time-based and usage-based PM triggers natively, with most also supporting condition-based work order generation.
Condition monitoring integration. Vibration sensors, oil analysis programs, thermal imaging cameras, and ultrasonic measurement equipment increasingly integrate with CMMS for automated condition-based work order triggering. Sensor data flows to CMMS through middleware platforms (OSIsoft PI, AVEVA PI System, Honeywell PHD), with threshold violations generating work orders automatically. This integration converts theoretical CBM into practical CBM by eliminating manual data review steps that programs at scale cannot sustain.
Connected worker platforms. Augmentir, Parsable, Tulip, and SwipeGuide deliver task instructions, training content, and inspection guidance to technicians on tablets and smart glasses. Step-by-step PM execution with photo verification ensures consistent execution across technicians and shifts. See our connected worker platform guide for the platform landscape.
Predictive analytics on PM data. Modern PM programs accumulate substantial data: PM completion records, failure history, condition monitoring trends, parts consumption, and labor utilization. APM platforms apply analytics to this data to identify PM optimization opportunities, predict failures, and recommend frequency adjustments. The analytics layer extends PM beyond schedule execution into continuous program optimization.
Integration with autonomous maintenance. Modern programs deploy operator-executable PMs within an autonomous maintenance framework rather than as separate schemes. The JIPM seven-step Jishu Hozen methodology defines how operators take ownership of equipment care, including the cleaning, lubrication, and basic inspection PMs that operators are best positioned to execute. PM and AM are complementary rather than competing – see our Autonomous Maintenance guide.
Honest Middle Ground: Why PM Programs Fail
PM programs fail more often than they succeed, and the failure modes are predictable. Acknowledging the failure modes is what differentiates serious reliability content from vendor-published content that systematically avoids the topics that conflict with software-as-the-answer narratives.

Building schedules without asset criticality analysis. The most common failure mode. Programs that assign PMs based on equipment list without criticality tiering treat all assets as equally important. The result is over-maintenance of non-critical assets (waste) and under-maintenance of critical assets (missed prevention). The cure is asset criticality analysis as a non-optional Step 2, not an optional refinement.
Applying uniform PM regardless of strategy fit. Programs that apply time-based PM to assets that warrant CBM or PdM produce inferior outcomes than the asset criticality justifies. Critical assets in the high-consequence tier often warrant condition monitoring rather than time-based scheduling, even when condition monitoring infrastructure investment is required. The cure is strategy selection per tier in Step 3, with RCM analysis on the most critical assets.
Using OEM-recommended frequencies without operating context adjustment. OEM recommendations are typically conservative starting points calibrated for average operating context. Equipment in benign service is over-maintained at OEM intervals; equipment in severe service is under-maintained. Programs that apply OEM frequencies uniformly across operating contexts produce both wastes and missed preventions. The cure is operating context categorization with frequency adjustments applied systematically.
Treating PM as a compliance activity rather than a reliability program. Programs measured primarily by PM compliance rate optimize for compliance regardless of whether PMs prevent failures. PM compliance of 95% with declining MTBF indicates the wrong PMs are being executed at the right frequency. The cure is outcome-based KPIs (MTBF, OEE, planned-to-unplanned ratio) alongside activity KPIs (compliance rate).
Iatrogenic maintenance from excessive PM activity. Joel Levitt’s term for maintenance work that introduces failure rather than preventing it. Common causes include over-frequent disassembly that introduces contamination, premature component replacement that exposes equipment to early-life failures (the steep portion of the bathtub curve), lubrication errors during PMs, and improper torque application. The “more PM is better” assumption is wrong — there is an optimal PM frequency beyond which additional activity reduces reliability rather than improving it. The cure is data-driven frequency optimization that retires ineffective tasks rather than adding more.
Inadequate technician training on PM execution. PM tasks executed inconsistently across technicians produce variable outcomes that mask program effectiveness. Programs that compress training to save calendar time consistently produce execution variability. The cure is sustained training investment with skills certification (CMRT for technicians, CMRP for engineering and management roles).
Missing CMMS infrastructure that prevents reliable scheduling and tracking. Operations attempting PM programs at scale without integrated CMMS infrastructure produce inconsistent execution, missed PMs, and audit findings. Spreadsheet-based PM tracking fails reliably above moderate asset counts. The cure is appropriate CMMS investment as a precondition for PM program scale.
Lack of cross-functional planning involvement. PM programs designed by maintenance teams alone often miss operations input on production schedules, reliability engineering input on failure modes, and procurement input on parts availability. The result is PMs that conflict with production schedules, miss the failure modes that actually drive reliability problems, or specify parts with long lead times. The cure is cross-functional planning teams during program design and ongoing review cycles.
Treating PM as a static program rather than continuously optimized. PM programs that work well at deployment deteriorate over multi-year periods as operating context evolves, equipment ages, and supporting data becomes stale. Programs without review cycles produce strong initial results that erode predictably. The cure is documented review cycles with frequency adjustment, task retirement, and task addition based on accumulated data.
Programs that succeed share strong asset criticality foundations, data-driven frequency setting, technician training investment, integrated CMMS infrastructure, and continuous improvement cycles. Programs that fail typically miss multiple of these elements, with the cumulative effect compounding over time.
Frequently Asked Questions
What is preventive maintenance?
Preventive maintenance (PM) is a proactive maintenance strategy where inspections, servicing, and component replacements are performed at predetermined time or usage intervals to prevent unexpected equipment failures and extend asset life. PM tasks are scheduled by calendar (time-based) or by operating data (usage-based) regardless of actual equipment condition. PM is one of several proactive strategies – alongside CBM and PdM – used in modern reliability programs.
What are the types of preventive maintenance?
The two primary types are time-based maintenance (calendar intervals) and usage-based maintenance (operating hours, cycles, miles). Both are scheduled regardless of actual equipment condition. Some sources group condition-based and predictive maintenance under a broad “preventive” umbrella, but the SMRP-aligned and RCM-aligned framing treats CBM and PdM as parallel proactive strategies rather than as types of PM. The distinction matters because the trigger logic and infrastructure requirements differ substantially.
Are condition-based maintenance and predictive maintenance types of preventive maintenance?
This is a contested classification. The SMRP-aligned framing – dominant among reliability engineers, RCM practitioners, and SMRP-credentialed professionals – treats PM, CBM, and PdM as parallel proactive maintenance strategies rather than as types of PM. PM is scheduled by time or usage regardless of condition; CBM is triggered by measured condition reaching an action threshold; PdM forecasts failure timing using analytics. Some sources, including Joel Levitt and several CMMS vendor publications, group all four under a “preventive” umbrella. This guide uses the parallel-strategies framing because it aligns with SAE JA1011, SMRP Body of Knowledge materials, and how reliability engineers select among strategies in practice.
What is the difference between preventive maintenance and predictive maintenance?
PM schedules tasks at fixed time or usage intervals regardless of actual condition. PdM uses analytics – historical patterns, condition monitoring trends, and machine learning – to forecast failure timing and trigger maintenance at the optimal point. PM has lower infrastructure cost but tends to over-maintain or under-maintain depending on actual equipment behavior. PdM requires sensor and analytics infrastructure but performs maintenance more precisely. Most mature programs use both based on asset criticality.
What is the difference between preventive maintenance and corrective maintenance?
PM is performed before failure to prevent it. Corrective maintenance is performed after failure to restore function. PM has predictable cost and scheduled downtime; corrective maintenance has unpredictable cost and unplanned downtime. Reliability engineering literature consistently reports emergency repairs cost several times more than equivalent planned maintenance. Mature operations target a high planned-to-unplanned ratio – common world-class targets are around 80/20, with reliability leaders reaching 90/10.
What are the benefits of preventive maintenance?
Reduced unplanned downtime, increased equipment availability, extended asset life, lower emergency repair premiums, regulatory compliance documentation, earlier defect detection, fewer equipment-related quality issues, and safer work environments. The magnitude of benefits depends on baseline maturity, asset criticality profile, and operating context. Reliability engineering literature documents substantial improvements over reactive-only operations.
How often should preventive maintenance be performed?
Frequency depends on asset criticality, OEM recommendations, operating context, and historical failure data. Critical assets typically warrant condition-based or predictive coverage rather than purely time-based PM. Important assets receive PMs at OEM intervals adjusted for operating context. Non-critical assets receive minimal PMs or run-to-failure. Frequencies are not universal — the same equipment in different services often warrants substantially different intervals.
What is iatrogenic maintenance?
Iatrogenic maintenance is maintenance work that introduces failure rather than preventing it, a term popularized by Joel Levitt. Common causes include over-frequent disassembly, premature component replacement, lubrication errors, and improper torque application. The “more PM is better” assumption is wrong – there is an optimal frequency beyond which additional PM activity reduces reliability. Avoiding iatrogenic maintenance requires data-driven frequency optimization rather than schedule expansion.
What KPIs should I track for a preventive maintenance program?
Primary KPIs include PM Compliance Rate, MTBF, MTTR, Planned vs. Unplanned Work Ratio, and Maintenance Cost as a percentage of RAV. Secondary KPIs include backlog age, schedule compliance, wrench time, and PM yield. SMRP publishes standardized definitions in its Best Practices guide — using SMRP definitions ensures consistent measurement and enables industry benchmarking.
How does preventive maintenance integrate with CMMS?
CMMS is the operational backbone. The CMMS stores asset records, schedules PM work orders automatically, generates task instructions and parts reservations, captures execution data, tracks compliance against scheduled targets, and produces audit-ready documentation. Modern CMMS platforms support time-based and usage-based PM triggers natively, with most also supporting condition-based work order generation through integration with sensor data and process historians.
Why do preventive maintenance programs fail?
Common failure modes include building schedules without asset criticality analysis, applying uniform PM regardless of strategy fit, using OEM frequencies without operating context adjustment, treating PM as compliance rather than reliability, iatrogenic maintenance from excessive activity, inadequate training, missing CMMS infrastructure, lack of cross-functional planning, and treating PM as static rather than continuously optimized. Successful programs share strong criticality foundations, data-driven frequencies, training investment, integrated CMMS, and continuous improvement cycles.
Related Guides
- Autonomous Maintenance: The Complete Guide to Jishu Hozen
- How to Calculate Asset Criticality
- How to Perform RCM: Reliability-Centered Maintenance Methodology
- How to Perform FMEA: Failure Mode and Effects Analysis
- How to Calculate MTBF and MTTR
- How to Calculate OEE
- Best CMMS Software: Independent Comparison
- Best Asset Performance Management Software
Sources & References
- SMRP Best Practices Guide – Society for Maintenance & Reliability Professionals
- SMRP Body of Knowledge – Equipment Reliability pillar (Pillar 3 of 5)
- SAE JA1011 – Evaluation Criteria for Reliability-Centered Maintenance (RCM) Processes
- SAE JA1012 – A Guide to the Reliability-Centered Maintenance (RCM) Standard
- ISO 55000:2014 – Asset Management – Overview, principles and terminology
- ISO 55001:2014 – Asset Management – Management systems requirements
- ISO 14224:2016 – Petroleum, petrochemical and natural gas industries – Collection and exchange of reliability and maintenance data for equipment
- ISO 18436-2 – Vibration Analyst certification categories
- Levitt, J. – Complete Guide to Preventive and Predictive Maintenance, 2nd Edition (Industrial Press, 2011)
- Moubray, J. – Reliability-Centered Maintenance II (Industrial Press, 1997)
- Moore, R. – Making Common Sense Common Practice: Models for Operational Excellence, 4th Edition
- Gulati, R. – Maintenance and Reliability Best Practices, 2nd Edition
This guide is reviewed and updated annually. Last review: May 2026. View all Reliable guides.