

Most companies don’t measure mean time between failures (MTBF), even though it’s the most basic measurement that quantifies reliability. MTBF is the average time an asset functions before it fails. So, why don’t they measure MTBF?
This metric is the average length of operating time between failures for an asset or component.
- Mean time between failures (MTBF) is usually used primarily for repairable assets of a similar type.
“FORMULA: MTBF = Operating time (hours) / Number of Failures”
- Mean Time to Failure (MTTF), a related term, is used primarily for non-repairable assets and components (e.g., light bulbs and rocket engines).
- Both terms are used as a measure of asset reliability and are also known as mean life. MTBF is the reciprocal of the failure rate (λ), at constant failure rates.
- This metric is used to assess the reliability of a repairable asset or component.
- Reliability is usually expressed as the probability that an asset or component will perform its intended function without failure for a specified period of time under specified conditions.
- When trending, an increase in MTBF indicates improved asset reliability.
- Maintenance Rework. This metric is corrective work done on previously maintained equipment that has prematurely failed due to maintenance, operations or material problems.
Reason 1
Work orders don’t capture all emergency work. Many companies have rules such as, “A work order will be written only if the equipment is down for more than one hour.” This rule doesn’t make sense. Let’s say, for example, a circuit overload on a piece of equipment trips 100 times a month.
Many times, small problems lead to major asset failure. Don’t wait until a small problem becomes a big one.
Start tracking MTBF and you’ll be on the road to reliability.
Start tracking MTBF and you’ll be on the road to reliability. Eventually, you’ll learn to manage your assets proactively according to their health. Then, you’ll see your MTBF improve dramatically.
Reason 2
Not every asset is loaded into the CMMS/EAM. This is a problem that makes writing an emergency work order impossible. If you’re not tracking every asset down to the component level, you can’t possibly identify any true reliability issue.
- Think about it this way; if 20% of your assets eat up 80% of your resources, wouldn’t you want to identify that 20%, the bad actors?
- Put all of your assets in your CMMS/EAM, track the MTBF and the bad actors will become obvious.
Reason 3
It isn’t important to measure MTBF because other metrics provide equivalent value. You can get asset reliability from other metrics, but keep it simple using MTBF.
- Count the number of breakdowns (the number of emergency work orders) for an asset during a given time interval.
- That’s all it takes to learn how long the equipment runs (on average) before it fails. This is not difficult to measure MTBF.
Reason 4
The maintenance organization is so reactive that there’s no time to generate any metrics. They’re constantly scrambling merely to react to the latest crisis. But, taking a small step in the right direction—tracking just one measure of reliability—will reveal that 20% of the assets burn 80% of the resources.
If you start with the worst actor, you’ll be surprised how quickly you can rise out of the reactivity quagmire.
For example, a plant manager who recently measured the MTBF for his “Top 10 Critical Assets” was shocked at the results. He expected the combined MTBF for these assets would be around eight to nine hours.
In the first month of this initiative, he found that the actual MTBF was 0.7 hours. You may find yourself in the same situation. You’ll never know the true reliability status on your plant floor until you begin measuring it.
Reason 5
There are too many other problems to worry about right now without being pressured to measure reliability. I’ve heard this many times, and it tells me that the organization is in total reactive mode. This organization deals only with the problem of the hour.
If 20% of your assets are taking 80% of your resources, dig out of the problem by attacking the assets that cause the most pain—the “high payoff assets” that will respond to a reliability improvement initiative.
Attack the assets that cause the most pain.
We’ve got to stop fighting fires. The characteristics of adept firefighters include:
- High turnover of personnel (mostly in production)
- Maintenance costs that continue to rise.
- Maintenance costs that are capped before the month ends (“Don’t spend any more money this month, We’re over budget”)
- Every day is a new day of problems and chaos.
- Maintenance is blamed for missing the production goals.
It isn’t easy to fight fires and initiate reliability improvement at the same time, but it can be done. Start measuring MTBF and attack the high-payoff assets.
You can’t change a company’s culture from reactive to proactive overnight, but you can eliminate reliability problems one major system at a time. That’s where you’ll find a rapid return on investment. Change people’s activities and behaviors slowly, and you’ll transition to a proactive culture.
Asset reliability is the key to keeping a company profitable, increasing its capacity, and reducing its maintenance cost.
Ensure you post a Maintenance and Reliability Scorecard for all to see and update it weekly.
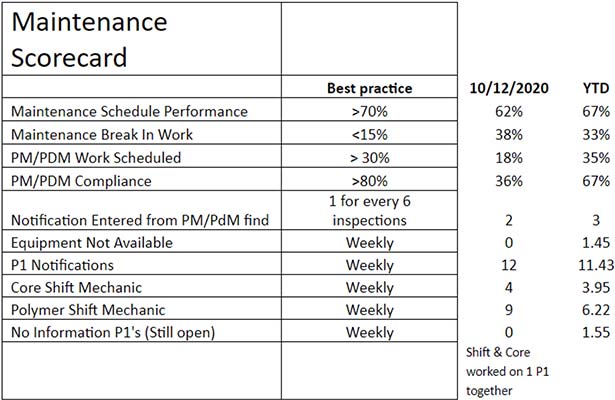
Last, if you want to ensure that everyone is performing the same maintenance and reliability functions, be sure you have well-defined Roles and Responsibilities using the RACI Process.

Ricky Smith, CMRP, CMRT is the Vice President of World Class Maintenance and a leading Maintenance Reliability Consultant with over 35 years of experience. He holds certifications such as Certified Maintenance and Reliability Professional (CMRP) and Certified Maintenance and Reliability Technician (CMRT). Ricky has worked with global companies like Coca-Cola, Honda, and Georgia Pacific, delivering expert maintenance solutions across 30 countries. His career began in the U.S. Army, advancing to leadership roles, including a position at the Pentagon as Facility Investigator for the Secretary of Defense. Ricky is also the co-author of Rules of Thumb for Maintenance and Reliability Engineers and Lean Maintenance: Reduce Costs, Improve Quality, and Increase Market Share.






