

Predictive maintenance is no longer a competitive advantage—it’s the cost of entry for modern industrial reliability. But having a PdM program and getting real value from it are two very different things.
Too many facilities are still chasing failures, reacting to late alarms, and missing critical issues—not because they lack technology, but because their strategy is broken. They’re monitoring what’s convenient instead of what matters, duplicating work between teams, and leaving failure modes unchecked.
Too many teams are monitoring what’s convenient instead of what actually fails.
This article digs into the most common breakdowns inside predictive maintenance programs—flawed coverage models, misaligned technologies, weak alarm strategies, and missing feedback loops.
It’s not about adding more sensors or checking things more often. It’s about building a smarter, tighter, consequence-based approach that turns detection into action. If your PdM program isn’t preventing the failures that hurt the most, this article will show you why—and what to do about it.
Stop Chasing Failures: Fix Your Criticality Coverage Blind Spot
A predictive maintenance program is only as effective as the decisions it makes based on what it monitors. In many industrial facilities, we often see the same mistake repeated: teams invest significant effort in monitoring large, expensive assets while overlooking smaller, less obvious components that can bring production to a halt.
The result? Plenty of equipment fails, and production is frequently disrupted, despite having a predictive maintenance program in place. Why? Because the program is designed only to check the “big stuff.” Meanwhile, critical but smaller items—such as gearbox sensors, fan belts, couplings, and relays—fail unexpectedly, causing downtime.
This issue stems from a flawed criticality coverage model. Too many programs define coverage based on the size or cost of an asset, rather than its true criticality—its actual impact on operations, safety, and cost when it fails.
A more effective approach is to base coverage levels on actual criticality, rather than relying on assumptions. It means asking:
- What happens when this fails?
- Will it stop the line?
- Is it hard to replace?
- Will it create a safety risk?
When we shift our focus to consequence-based prioritization, we stop reacting to problems and start preventing the failures that matter most. You don’t need to monitor every asset. You need to monitor the ones that would hurt you the most if they were to go down.
A mature, high-performing maintenance program:
- Evaluates failure impact, not just asset value
- Covers assets regardless of size if their failure has high consequence
- Eliminates downtime blind spots by filling in gaps left by traditional coverage strategies
If your facility continues to experience frequent failures despite having predictive maintenance in place, it’s time to reassess your coverage model.
What are you missing? And more importantly, why are you missing it? The answers might not be in the big machines. They’re often hiding in the small, silent, overlooked components that no one thought to watch.
It’s time to rethink where you aim your preventive maintenance efforts—not everywhere, just the right places.
Are Your PdM Technologies Solving the Right Problems?
Many industrial facilities proudly claim they’ve implemented predictive maintenance. They’ve purchased sensors, rolled out dashboards, and set up alerts. Yet, failures still occur—failures that the program never saw coming. Why? Because the technology coverage model is broken.
Here’s the hard truth: most PdM programs are built around the tools they already have, not the failure modes they actually face.
This leads to a dangerous blind spot. You’re experiencing failures that aren’t being caught, not because they’re unpredictable, but because you’re not using the right technology for the failure mode. Vibration analysis won’t catch electrical arcing. Thermography won’t detect oil contamination. Ultrasound won’t reveal shaft misalignment.
When PdM technology coverage is insufficient for the most reasonable and likely failure modes, you’re not preventing failure—you’re just monitoring what’s convenient.
You’re not preventing failure—you’re just monitoring what’s convenient.
To build a truly effective PdM program, you must reverse the order of planning:
- Start with failure modes—what are the most likely and most costly ways your assets fail?
- Match technologies to those failure modes—choose tools that can detect those specific issues early and reliably.
- Ensure a high percentage of coverage—make sure your PdM design captures as many high-risk failure modes as possible.
This is what a sound technology coverage model looks like. It’s not about using the latest gadgets or having the most sensors installed. It’s about ensuring your technologies are aligned with your real operational risks.
Facilities that succeed with PdM aren’t necessarily the ones spending the most—they’re the ones thinking the best. They analyze failure modes first, then build their technology stack to intercept those failures.
If you’re still being surprised by preventable breakdowns, it’s time to ask the tough question: Are we using the right tools for the right problems? If the answer isn’t a confident yes, then the failure isn’t with the machine—it’s with the model.
Build your PdM around failure modes, not just features. That’s where real reliability begins.
Why Your Sensors Aren’t Saving You: The Hidden Limits of Overall Levels
Many industrial facilities believe that because they’ve installed vibration sensors, they’re covered. Data is streaming in 24/7. Dashboards are live. Alerts are set. And yet…failures still happen.
The problem? Overreliance on overall vibration levels.
While overall signal levels are a useful metric, they are also a blunt instrument. They give you a high-level indication that something is changing, but they rarely tell you what or why. Worse, they often don’t move until it’s already too late.
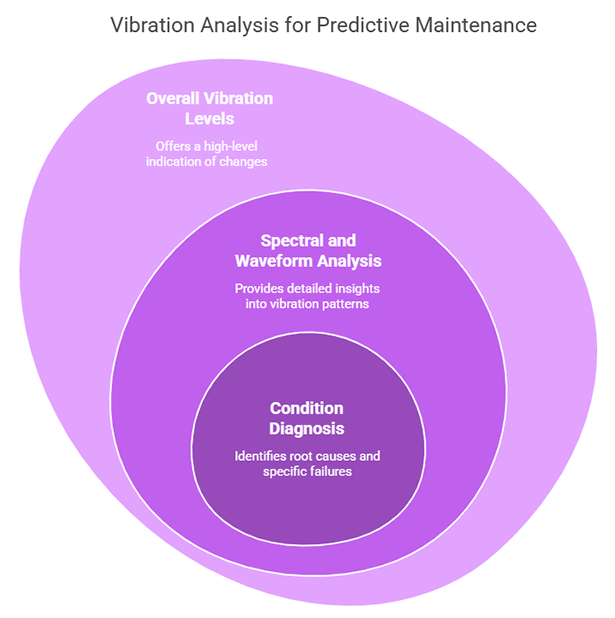
Facilities that only monitor overall levels are essentially waiting for damage to grow large enough to be visible at a high level before acting. That’s not predictive maintenance—that’s deferred reactive maintenance.
The real power of condition monitoring lies in spectral and waveform analysis. These methods allow you to:
- Identify fault types early (e.g., bearing wear, misalignment, imbalance)
- Track the progression of specific failure modes
- Diagnose the root cause before the problem escalates
When you move beyond overall levels and analyze the vibration spectra and waveforms, you’re no longer watching for a fire—you’re spotting the smoke. You gain visibility into the exact nature of the issue while there’s still time to act without disrupting production.
Facilities that succeed with vibration-based predictive maintenance don’t stop at “green/yellow/red” indicators. They look deeper. They understand that raw signal data holds the truth, not just the summary statistics.
If you’re still experiencing failures even with constant sensor coverage, the issue isn’t the hardware—it’s the lack of depth in your analysis.
Shift your mindset from general monitoring to condition diagnosis. Teach your program to look beyond the surface. That’s where the insight lives—and where the real reliability begins.
Your sensors are capable of telling a detailed story. The question is: Are you reading it, or just watching the headline?
Your Alarm Limits Are Too Late: Why You’re Still in Emergency Mode
In too many industrial facilities, predictive maintenance data looks great—until it’s time to act. By then, it’s already a scramble. Equipment is failing, production is interrupted, and the team is working around the clock to avoid shutdowns.
The issue isn’t the data. It’s the alarm limits.
Most PdM systems are configured to flag conditions only when things get really bad. These thresholds are so high that by the time an alarm goes off, you’re already well down the P-F Curve—in the zone of degradation where failure is near and options are few. Instead of driving proactive planning, the alarms simply mark the start of another reactive event.
If your alarm triggers panic, it’s already too late.
If your team has to “jump through hoops” to avoid emergency action every time an alert is triggered, your alarm limits are set too high.
Effective predictive maintenance means more than monitoring—it means designing your system to act early. That starts with setting alarm limits low enough to trigger meaningful, proactive work. You want to catch degradation when it begins, not when it’s about to cause a breakdown.
Well-calibrated alarm limits should:
- Detect early signs of failure, not just catastrophic ones
- Create time for response planning, not last-minute interventions
- Drive low-cost maintenance actions, not high-cost emergency repairs
This isn’t about generating more alerts—it’s about generating the right alerts. Early, actionable insights that support planning, not panic.
A mature reliability program understands that alarm thresholds are strategic tools, not just technical settings. They define how early you detect issues, how much flexibility you have to schedule work, and how effectively you avoid unplanned downtime.
If you’re constantly in firefighting mode despite having PdM data, it’s time to revisit your alarm strategy.
Don’t wait for a crisis to trigger a response. Set your system to see it coming.
That’s what separates a reactive facility from a truly proactive one.
Broken Feedback Loops Are Breaking Your PdM Program
A predictive maintenance program is only as effective as the people who use it, and the way they work together. Unfortunately, in many facilities, there’s a major disconnect between the PdM technicians and the maintenance crafts personnel who actually execute the work.
When feedback loops are broken, the predictable result is a lack of cooperation, no follow-up, and no improvement. PdM techs identify problems, but the findings don’t get acted on. Maintenance crafts perform work, but insights don’t make it back to the PdM team for learning and refinement.
These two groups operate in organizational silos, and it’s costing your plant real reliability.
A healthy predictive maintenance program depends on tight coordination. It’s not enough for each group to do its job well—they must do it together. That means:
- Sharing information about asset condition, maintenance actions, and failure causes
- Following up on work orders with feedback to PdM teams
- Collaborating on root cause investigations and reliability improvements
Without these feedback loops, issues repeat. Data becomes stale. Alarm credibility drops. And ultimately, the PdM program loses its value.
The solution is not more technology—it’s better workflow design. You must create processes that require collaboration between PdM and maintenance crafts. Build it into your CMMS. Make it a step in every predictive maintenance task. Hold joint reviews after critical interventions.
True reliability isn’t found in the sensor data—it’s found in the conversations, corrections, and continuous learning that happen between the people responsible for keeping the plant running.
If your predictive maintenance program feels stuck, look at your feedback loops. Are you closing them? Or are teams working side-by-side without ever really working together?
Collaboration isn’t optional. It’s the missing piece between data and action.
Until you fix the handoff between detection and execution, your PdM program will never reach its full potential.
Stop the Chaos: Standardize Your Alarm Limits Before It Costs You
If your predictive maintenance program feels unpredictable, there’s a good chance the problem lies in how your alarm limits are set.
Across many industrial facilities, we see the same issue repeat: similar components—identical motors, pumps, or bearings—each have different alarm thresholds for the same faults. This creates confusion, inconsistency, and a lack of trust in the data.
The root cause? Every machine is treated like it’s special and unique, even when it’s not. This leads to custom alarm tuning on a case-by-case basis, which might seem thoughtful, but results in chaos. When technicians can’t rely on consistent standards, they don’t know when to act or what the data means. It slows down decisions and undermines the program.
To eliminate this noise, you need to institute standardized alarm limits. These limits should be based on objective, engineering-driven parameters like:
- Bearing type
- Shaft speed
- Component type
When alarms are consistent across similar assets, it:
- Reduces confusion and error
- Speeds up analysis and decision-making
- Improves training and operator confidence
- Strengthens program credibility
This isn’t about treating every machine the same—it’s about applying repeatable logic where it makes sense. You’ll still make exceptions for unique assets, but the baseline should be a structured, rules-based approach that delivers clarity.
The best PdM programs don’t guess. They engineer consistency into their alarm logic. They understand that standardization is a prerequisite for scale.
If your team is overwhelmed by alerts or unsure when to act, don’t blame the sensors. Look at your alarm framework.
Are your thresholds strategic—or are they ad hoc and arbitrary? The answer makes the difference between noise and insight, between failure and foresight.
Standardize your alarms. Simplify your response. Strengthen your reliability.
Where’s the Work? Why Your PdM Program Isn’t Delivering Results
You’ve invested time, money, and resources into building a predictive maintenance program. You’ve trained technicians, installed sensors, and collected mountains of data. But when you look at your actual maintenance backlog, only a small amount of work is being driven by PdM.
Sound familiar?
This is a common problem in industrial facilities where PdM corrective work is not formally embedded into the workflow. Despite all the effort, the system isn’t producing enough actionable results. That means you’re not realizing the full return on your PdM investment.
The reasons are clear:
- Low coverage models mean many failure modes go undetected.
- Broken workflows mean that even when problems are detected, they aren’t translated into formal work orders.
- Lack of structure around how PdM findings become maintenance actions leaves critical insights stuck in reports or ignored entirely.
A predictive maintenance program isn’t successful because it collects data. It’s successful when it drives real corrective work that prevents downtime. And that only happens when the program is built into the fabric of your maintenance process.
To address this, you need to formalize the PdM element of your workflow, particularly in terms of work identification. Every validated finding should follow a consistent process that results in:
- A clearly defined work request
- Prioritization based on risk and criticality
- Integration with your CMMS for execution and tracking
This is what turns PdM from a technical exercise into a reliability driver. When the process is clear and repeatable, your PdM program becomes a source of strategic value, not just noise.
If you’re wondering why you’re not seeing more PdM-driven jobs, don’t assume the technology is broken. Ask yourself if the workflow is missing.
Make PdM part of how work gets done, not just part of how data gets collected. That’s how you move from insight to action and turn prediction into prevention.
Are Your PM and PdM Teams Duplicating Effort? Stop the Overlap, Start the Optimization
If you’re running a predictive maintenance program alongside a traditional preventive maintenance strategy, it’s time to ask a tough question: Are your teams checking the same things twice?
Many facilities fall into this trap. Predictive maintenance technicians use advanced tools to monitor condition, while PM mechanics and electricians continue to inspect the exact same components on a time-based schedule. This duplication creates confusion, frustration, and inefficiency. It also leads to conflicting reports about equipment health—who do you trust: the manual inspection or the sensor data?
If PM and PdM are checking the same thing, one of them is wasting time.
This type of overlap indicates an ineffective balance between PM and PdM proportions. The whole point of predictive maintenance is to replace calendar-based guesses with data-driven insights. When the two programs are allowed to operate independently, you’re not leveraging the strengths of either.
To solve this, you need to remove PM tasks that are already covered by PdM for the same failure modes. This doesn’t mean eliminating all PM work—it means being strategic. Ask:
- Is this PM task still adding value?
- Is PdM already monitoring this failure mode with higher accuracy?
- Are we wasting technician time that could be better spent elsewhere?
By aligning and streamlining the two programs, you:
- Eliminate redundant work
- Reduce labor hours spent on low-value tasks
- Increase trust in PdM outputs
- Improve clarity around equipment health
This is where reliability programs mature—when organizations move from stacking programs to integrating them into a cohesive strategy.
If your facility is still running PMs on components already monitored by PdM, it’s time for a review. Use failure mode analysis to identify overlap and optimize the proportions of PM vs. PdM.
Maintenance isn’t about doing more—it’s about doing the right things at the right time. Don’t let tradition block progress. Align your PM and PdM programs, reduce confusion, and make every task count.
Missed Failures Are Missed Opportunities: Why Every Breakdown Deserves a Second Look
In industrial maintenance, every unexpected failure is a message—but are you listening?
Too often, facilities treat unplanned failures as isolated incidents. They fix the problem, move on, and hope it won’t happen again. However, this reactive mindset leads to repeated issues, wasted resources, and reliability programs that never truly deliver improvement.
What’s missing? A commitment to treating every unexpected failure as a missed opportunity.
When a failure isn’t investigated, you lose the chance to understand:
- What warning signs were missed
- Whether PdM coverage was in place and effective
- If the component was deemed critical, and why
- How the workflow might have failed to trigger action
Without this feedback loop, maintenance programs become blind to their own gaps. There is confusion about which assets are critical, and inconsistent decisions about which failures receive attention. Some are investigated thoroughly. Others are ignored. The result? No clear priorities and no clear path to improvement.
To change this, make it policy to investigate all unexpected failures as missed opportunities, not just the big ones. Treat them as case studies. Learn from them. Ask:
- Was this failure predictable?
- Was this failure preventable?
- What needs to change in our PdM or PM approach to catch this next time?
This doesn’t mean assigning blame. It means using failure as a learning tool. Every unplanned downtime event holds the potential to make your systems stronger, smarter, and more proactive.
Facilities that take this approach develop a culture of continuous reliability improvement. They know that success doesn’t come from never failing—it comes from never ignoring what failure can teach you.
If you want to evolve your predictive maintenance program, start with the failures you didn’t see coming. They’re not just breakdowns. They’re the blueprint for what to fix next.
Stop skipping the lessons. Start capturing the opportunities.
You’re Checking the Wrong Things Too Often—and Not Enough of the Right Things
When it comes to predictive maintenance, many facilities fall into a costly trap: inspection frequency is driven by perceived criticality, not by actual failure behavior or risk.
It sounds logical at first—check “critical” equipment more often, right? But here’s the problem: using the same PdM technology more frequently on certain components doesn’t necessarily improve your coverage or prevent failures. In fact, it can create blind spots.
Overchecking the wrong assets won’t save you from ignoring the right ones.
PdM tools are designed to detect specific failure modes. Their effectiveness comes from applying the right technology to the right failure mode at the right interval. Over-inspecting one asset doesn’t compensate for ignoring others. And inspection frequency should be based on the failure mode’s behavior, not just the perceived importance of the asset.
Many organizations mistakenly believe that criticality equals inspection frequency. But in reality, inspection strategy should be built around risk and reliability, not just hierarchy or cost.
The key is to create layers of protection, not by inspecting more often, but by designing redundant technology strategies based on actual equipment risk. For example:
- Use vibration analysis for mechanical faults
- Add infrared for thermal monitoring
- Incorporate ultrasound or oil analysis where relevant
This layered approach ensures that failure modes are covered, not just that assets are frequently checked.
Also, don’t neglect low-cost or less-visible assets. If their failure can stop production or cause safety concerns, they deserve thoughtful inspection planning too. Criticality should drive redundancy and technology mix, not just inspection frequency.
To level up your PdM strategy, review your current inspection plan:
- Are we checking the right things?
- Are we using the right technology for the failure mode?
- Are we relying too much on repetition and not enough on coverage?
Smart maintenance isn’t about checking more—it’s about checking smarter. Build layers, not loops. And make every inspection count toward real reliability.
Fix the Gaps, Prevent the Failures
Predictive maintenance programs hold tremendous potential—but only when they are properly aligned with the realities of asset failure, operational risk, and maintenance workflow. As this report has shown, many organizations struggle not because of a lack of technology or data, but because of poor strategy, misaligned processes, and overlooked execution details.
We’ve examined the key reasons PdM programs often fall short: criticality coverage that ignores smaller, high-impact components; technology mismatches that leave failure modes unmonitored; overreliance on high-level vibration signals; alarm thresholds set too high to allow proactive action; and disjointed communication between PdM teams and maintenance personnel. We’ve also explored how inconsistent alarm standards, poor work identification practices, and duplicated effort between PM and PdM can waste valuable resources and erode confidence in the system.
Finally, we emphasized the importance of treating every unexpected failure as a learning opportunity, rather than just another event to fix and forget.
PdM doesn’t fail from lack of data—it fails from lack of design.
The solution isn’t always more sensors or more frequent checks—it’s smarter design. Effective PdM programs are built around the most likely and most costly failure modes, supported by the right technologies, and integrated into formal, closed-loop workflows that ensure follow-up action.
To move forward, organizations must shift from reactive recovery to predictive precision. That requires stepping back, reevaluating assumptions, aligning inspection strategies with real risks, and embedding PdM insights into the broader maintenance and reliability culture.
If you want fewer surprises, lower costs, and higher uptime, the time to act is now. Rethink your coverage. Recalibrate your alarms. Reconnect your teams. And above all—build a PdM program that’s designed to prevent failure, not just monitor it.
The opportunity for transformation is real. Let this article be your starting point.








